coopoo 1 3 1 modularite
1.3.1 Structuration, modularité,
indépendance, encapsulation.
Structuration:
Face
à un gros problème, on cherche à le décomposer en plusieurs petits problèmes
plus accessibles.
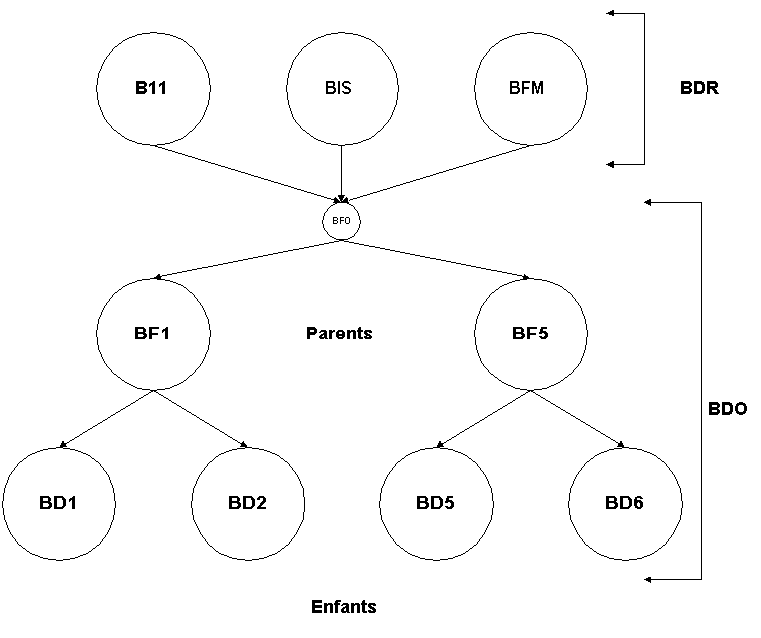
Dans notre cas: face à une grosse base B11 + BIS
on en fait plusieurs petites: + BF1 BD1 BD2 BF5 BD5 BF6
Modularité:
Au
lieu d'une grosse procédure linéaire, on fait plusieurs modules séparés plus
faciles à programmer et modifier.
Pour
RTGE au lieu d'avoir une seule procédure de constitution du folio 1 on la décompose
en plusieurs étapes qui sont:
1 lecture pour
charger BF1
2 calculs pour
charger BD1
et seulement après:
3
totalisations
4 mise en
forme pour charger TF1
Modularité de compréhension:
Etant
donné qu'on sépare les folios de synthèse et les folios de détail avec, pour
chaque classe ses propres caractéristiques, ses propres bases, ses propres procédures
et tables paramètres, il devient plus facile de comprendre le folio 5 sans être
gêné par ce qui ne concerne le folio 1 alors qu'auparavant les folios
partageaient les mêmes bases et tables paramètres et se trouvaient en
situation de conflit ou contagion de bugs.
Grâce
à la modularité nouvelle, deux personnes peuvent programmer les deux ensembles
(synthèse et détail) en parallèle sans avoir besoin de connaître l'autre côté
ou de l'attendre.
Modularité de protection:
L'entrée
de chaque module est protégé avec un sas propre à ce module (différent de la
porte d'entrée de l'autre module). Grâce à cet interface, on peut vérifier
la conformité des données en entrée (conformité aux standarts acceptables
par le module) et en sortie. Les données publics (connues par les modules amont
et aval) sont limitées et bien définies et ne sont pas affectées par les
variations des données privées (qui dépendent des variations de la
programmation ultérieure à l'intérieur de chaque module). Les données
faiblement variables sont bien définies (tables finales d'une tâche) et les
données fortement variables sont bien encapsulées à l'intérieur des modules
(table intermédiaires d'une tâche).
Indépendance:
On
essaie d'augmenter l'indépendance des modules les uns par rapport aux autres
pour pouvoir les développer séparément et éviter que les bugs ne noient ou
ne se propagent dans un grand volume de codes. L'indépendance vient de la
modularité et dépend du faible couplage entre modules.
Chaque
module est indépendant, il subit moins les erreurs et bugs en amont et il
envoie moins de bugs vers l'aval. Alors qu'auparavant on avait une seule procédure,
maintenant on a autant de procédures que de bases.
exemple: niveau 1 : BDR = toutes les données RTGE
niveau 2 : BF1 = folios de synthèse
BF5 = folios de détail
niveau 3 : Bd5 = période d'analyse
Bd6 = comparaison
Chaque petite procédure résultant du découpage de la
grande procédure devient plus vérifiable, plus facile à relancer et plus
rapide à retourner en cas de plantage.
Exemple 1 relance: au lieu de relancer le tout en 5
heures, on relance la partie plantée en 1 heure de temps CPU.
Exemple 2 recherche d'erreur:
au lieu de tout rescanner sur 100 queries en cas de bug, on vérifie d'abord les
10 tables permanentes en sortie des modules principaux puis les quelques queries
à l'intérieur du module boggé. La moyenne de la recherche sur 10 tables est 5
tables. La moyenne de la recherche sur les 4 queries d'un module est 2 queries.
La moyenne de la recherche sur un système décomposé en modules comme le rtge
96 est de 5 + 2 = 7 queries à vérifier alors que la moyenne de la recherche séquentielle
sur 100 queries est de 50 queries. Conclusion: au lieu de vérifier 50 queries
en moyenne en cas de bug difficile, il ne reste plus que 7 queries en moyenne à
vérifier en cas de bug difficile.

Exemple 3. localisation des interventions évolutives:
Lorqu'une ligne change de place dans un état, cela ne touche pas la lecture
donc la zone d'intervention est plus petite et plus précise qu'avant: elle se
trouve dans la partie aval avec les calculs et mise en forme.
Exemple: Lorsqu'une ligne change
d'origine (de TAB elle passe à SICOGE ou FM) cela ne touche que la partie
lecture et pas la partie mise en forme.
Ainsi le découpage préalable des fonctions facilite la
modification ultérieure.
Objet:
Un
objet c'est une procédure plus des données privées
Un
objet communique avec l'extérieur par un interface d'entrée sortie.
Dans
RTGE un objet c'est une base (exemple BD1)
plus
les queries qui la chargent.
Un
objet c'est : entrée-traitement-sortie, bien séparé des autres objets
Dans
RTGE c'est la base (base = table données + tables paramètres) plus les queries
pour cette base.
exemples de bases: BD1 BD2 BD5 BD6
Un
objet a des données privées.
Dans
RTGE chaque base BD1 BF1 BD2 BF5 BD5 BD6 a des
tables données et paramètres spécifiques.
Paragraphe
3: Encapsulation.
L'objet
a ses propres données privées non accessibles aux autres objets. Un objet a
des frontières bien nettes.
Un
objet est composé des données plus les procédures (exemple: objet BD5 =
queries QLBD5CGK + tables BP5 BA5 BT5 + table BD5 ...)
Les
données d'un objet sont distinctes des données des
autres objets contrairement aux vieux sous-programmes qui
partagent des données et donc peuvent partager des virus comme plusieurs
personnes qui mangeraient dans le même bol de soupe avec la même cuillière.
La
modernité demande que chaque module possède ses propres données où il peut
mettre ses propres bugs sans contaminer les autres et sans être contaminés par
les autres. S'il a des bugs on peut les repérer à la sortie. S'il n'a plus de
bugs on ne peut plus en réintroduire par l'entrée car elle est contrôlée.
Cela fonctionne comme dans une cantine moderne où chacun a son plateau pour éviter
les risques d'épidémies.
Dans
le nouveau RTGE 96 chaque base a ses propres tables paramètres: la BF1 a ses
BP1 BP2, la BF5 a ses BP5 BP6, chaque tâche (lecture, calcul) a ses propres
bases. Ce n'est plus comme quand on avait une seule base fourre-tout et une
seule table paramètres à l'intérieur de laquelle les folios 5, 6, 7, 8 gênaient
les folios 1 2 parceque leurs besoins respectifs étaient différents.
Dans RTGE 96 l'objet c'est la base et ses queries
Exemple : la BF1 a sa table données
BF1
ses tables paramètres
BP1 BP2 BT1 Ba2
ses queries
BF1
différentes
de celles de la BIS ou la BD1 ou la BF5
Par ce principe, les spécificités du folio 5 ne gênent
pas le travail du folio 1 et les contraintes du folio 1 ne dérangent pas les
paramètres du folio 5.
L'encapsulation
donne des frontières solides, qui stoppent les bugs à la porte d'entrée.
La porte
d'entrée unique c'est l'interface d'entrée dans un module.
L'entrée
d'un objet classique est un message qui contient des données, des paramètres ,
le nom de l'objet et les fonctions à déclencher à l'intérieur de l'objet.
L'entrée
d'un objet RTGE c'est la base en amont qui lui fournit des caractéristiques à
hériter et détermine les caractéristiques de l'objet en aval.
Par le principe d'encapsulation, les données et les procédures appartenant à une fonction sont mis à un seul endroit. Ainsi, les erreurs de cet endroit ne contaminent pas d'autres endroits, et les modifications de procédures sont bien localisées pour l'évolution future. Les données d'une fonction appartiennent en privé à cette fonction.
un module, objet, package comme la bdr ou l'état de synthèse peuvent être développés et maintenus par un spécialiste PB indépendamment d'un autre package comme l'état de détail qui sera écrit et géré par AV qui sera expert en état de détail et chaîne mensuelle. Un package bien indépendant modulaire comme l'état de synthèse pourra être donné et reproduit dans la chaîne mensuelle et réutilisé dans la chaîne annuelle sans être mélangé attaché avec le package détails.
Un package comme la constitution de la BDR peut être traité séparément par
un spécialiste M.PL sans que les autres utilisateurs spécialistes des état de
sortie M.PB et M.AV puissent avoir besoin de comprendre le fonctionnement
interne pour pouvoir utiliser cette BDR Voilà les avantages de l'encapsulation
cela rend portable et faciliment réutilisable les modules, les bouts de
logiciels, les objets, les classes, les packages.
Technique
de traçage des nouvelles frontières de modules dans RTGE 96:
1°) Frontières verticales:
*
entre folios 1 2 d'une part et 5 6 d'autre part
*
entre folio 1 et 1
*
entre folio 5 et 6
2°) Frontières horizontale:
*
entre différentes étapes de traitement pour un folio:
1 lecture, 2 calcul, 3 taux, 4 mise en forme
Conséquences des nouvelle frontières de modules:
*
Les folios 1 2 d'une part et 5 6 d'autre part n'ont plus les mêmes
tables de paramètres:
- séparation entre BA2 et BA5 (codes d'affichage différents
car maquettes différentes)
- séparation entre BT1 et BT5 (comportements différents pour les
taux)
- séparation entre BP1 et BP5 (libellés différents selon le niveau
de synthèse ou de détail).
*
Chaque étape (calcul, taux, mise en forme...) a ses propres tables
paramètres avec des spécifications et fonctionnalité différentes
diversifiées, et souples, bien adaptées au traitement spécifique de
l'étape.
Effet des nouvelles frontières de modules:
*
Chaque changement futur dans la maquette sera très précisément localisé dans
le système de paramétrage. La modification des paramètres pour l'évolution
des états sera beaucoup plus précise, simple et rapide que lorsqu'il n'y avait
qu'une seule table paramètres qui mélangeait identifiants de stockage, paramètres
de calcul et codes d'affichage et qui tenait compte simultanément de tous les
folios sur une même ligne de codes.